

s640正12面体を押し込む途中に_6fig.jpg
—–—–—–
私が「7つの紙工作プロジェクト」の中で,躊躇なく「五角形スライド式テンプレート」を選んだのにはいくつかの伏線があります。
その❶
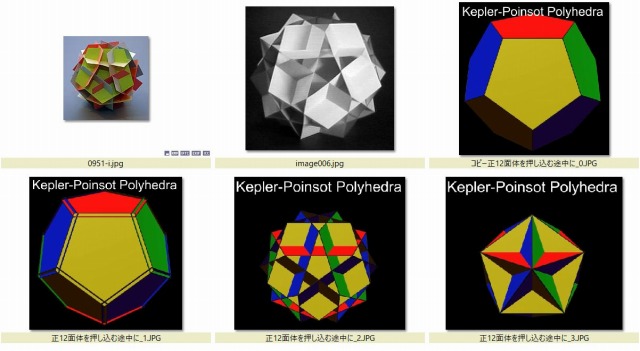
YouTube にある Professor Polyhedron (多面体教授)の《Kepler-Poinsot Polyhedra.mp4》に「正5角形の各面を面心を繋ぐ対称軸に沿って押し込んでいくと…」という変化をとらえた次の動画を見ていたことがあります。
ケプラー・ポアンソ多面体 6分29秒ありますが日本語訳された音声が流れます。動画の説明欄に「オートダビング版」と表示されています。
—–—–—–
Professor Polyhedron (多面体教授)の動画に関しては,正二十面体の星形図と星形の構成について興味深く鑑賞しましたが,学ぶことがいっぱい詰まっていそうなたくさんの動画のまだごく一部を見たにしかすぎません。今後時間がかかったとしても,折に触れて,つぶさに,確認してみたいと考えているところです。
—–—–—–
その❷
GeorgeHart-Math_YouTube.JPG
George Hart 博士の【最上位レベルの目次】で ・My YouTube Videos (showing math is cool)をクリックすると66本の動画が登録されていますが,その中に今考えている 『Seven Slide-Together Constructions(7つの紙工作プロジェクト)』があります。
*****
【7/25割込み投稿について】
先週末に投稿を行いました。よろしければご覧ください。
【数学の話題】